S+U images Adversial Training
CVPR2017论文 Learning from Simulated and Unsupervised Images through Adversarial Training
文章主要提出的几个新idea:
- 用无标签的图像以及合成图像进行学习,让图像更真实
- 训练一个refine网络对合成图像进行对抗学习
- 对GAN进行了一些修改,让训练更稳定,主要是后文提到的history和local patch
S+U Learning

整个框架还是沿用的GAN的架构,
G网络:用simulator合成的图像作为refine network的输入。
D网络:把前面的refine network的输出和unlabelled图片作为输入,输出判别是真是图片还是虚假图片。
G网络的loss在GAN的基础上增加了一个regularization loss,主要是因为G网络的输入是带标签的合成数据(比如使用的gaze image,是有gaze direction的,而整个实验最后还是为了用来提高监督学习的效果)。loss表示成
$$L_R(\theta) = \sum_{i} l_{real}(\theta; \hat{x}i, y) + \lambda l{reg}(\theta;\hat{x}i, x_i)$$
,其中第一项loss是对抗loss,即$l{real}(\theta;\hat{x}i,y)=-\sum{log(1-D{\phi}(R_{\theta}(x_i)))}$,$D_{\phi}$是判别器的输出,表示图片是合成图片的概率,可以发现这个loss越小,那么合成图像越难以分辨($1-D_{\phi}(R_{\theta}(x_i))$越大)。$ l_{reg}=||R_{\theta}(x_i)-x_i||_1 $使得输入和输出相似。而判别器的loss就是GAN的loss,这里就不写出来了。
改进
主要的改进点在最开始的地方已经写过了,一个是local patch,一个是history,下面分别介绍。
local patch adversarial loss
因为GAN在训练的时候会出现artifacts的情况,具体来说就是图片没有意义,但是loss很小,原因应该是学习的feature是判别器不容易判别的feature。讲artifects的文章可以看看distill。为了解决这个问题,作者提出用local patch作为单位(对判别器而言),对原始图像最后卷积成w x h的图像,w和h是图像被分成的patch大小,然后判别器的对抗loss变成交叉熵loss的和(The adversarial loss function is the sum of the cross-entropy losses over the local patches. 这段看原文可能更清楚一点)。
history
这个方法主要是为了应对两个问题:
- 在对抗学习过程中,因为不同的训练样本服从的分布还是有区别的,如果仅仅使用refine network最近的输出作为输入,那么容易出现divergency。
- refine network可能会产生判别器遗忘的artifects。
第一个问题,我认为不解决的话需要调超参,比较麻烦,但是通过引入历史的refined images能提高多少,我觉得效果应该也不会很好,毕竟合成图像也是随机生成的。
第二个问题应该能够有很大的改善。
具体实现就是保存一个refined images的池,在每次训练判别器的时候,minibatch输入有一部分是从池中选取,一部分是G网络产生。
实验
实验用了两个数据集,一个是MPIIGaze,一个NYU Hand。
先是展示了一下生成器生成图像的真实性,用了一个表还有几张图片,可以看出生成图片还是很逼真的。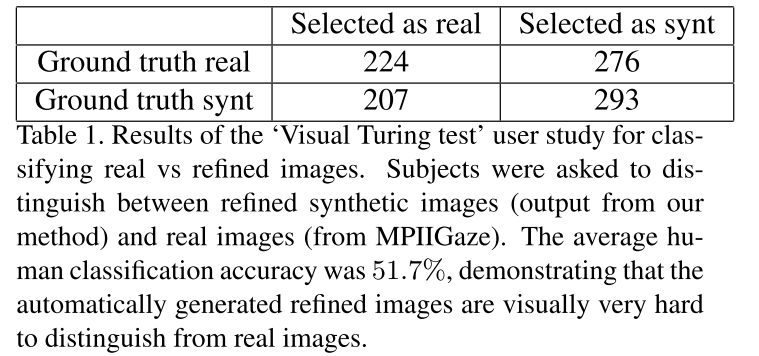
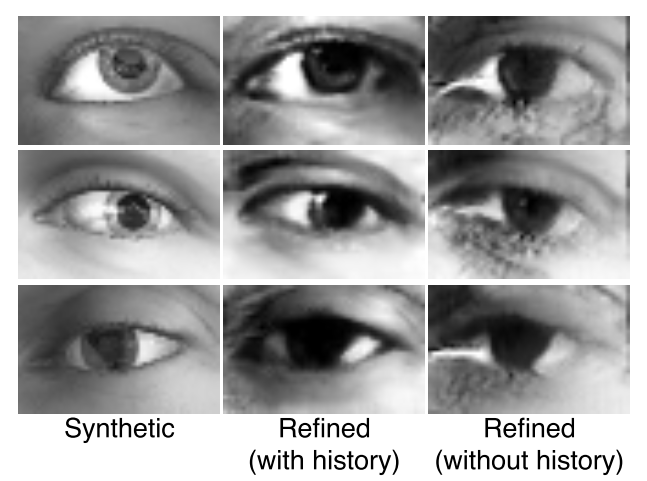
具体实验结果就不放了,大家可以直接去看论文。