A Survey of Appearance Models in Visual Object Tracking
最近看的一篇综述论文 http://arxiv.org/abs/1303.4803
What’s difficult in this research?
研究的难点?
Handling complex object appearance changes caused by factors such as illumination variation, partial occlusion, shape deformation, and camera motion.
目标可能由于旋转、遮挡、形变的原因导致外形变化。
Introduction
appearance modeling
The most important issue is effective modeling of the 2D appearance of tarcked objects.
主要需要解决的是对2维目标的外观建模,分解成了视觉表达和统计建模。
The appearance modeling is decomposed into this two stage:
- visual representation
- statistical modeling
overview of object tracking
The typical object tracking system is composed of four modules
- Object Initialization. manual or automatic, manual is performed by user to annotate the object, automatic is achieved by object detectors.
- Appearance Modeling. It consists of two components: visual representation and statistical modeling.
- Motion Estimation. This is formulated as a dynamic state estimation problem:
$x_t = f(x_{t-1},v_{t-1})$ and $z_t = h(x_t,w_t)$
where $x_t$ is the current state, $f$ is the state evolution function, $v_{t−1}$ is the evolution process noise, $z_t$ is the current observation, $h$ denotes the measurement function, and $w_t$ is the measurement noise. - Object Localization.
整个目标跟踪系统被分成:1、目标初始化;2、外观建模;3、运动预测;4、目标定位。
The Orgnization of the survey likes the figure under.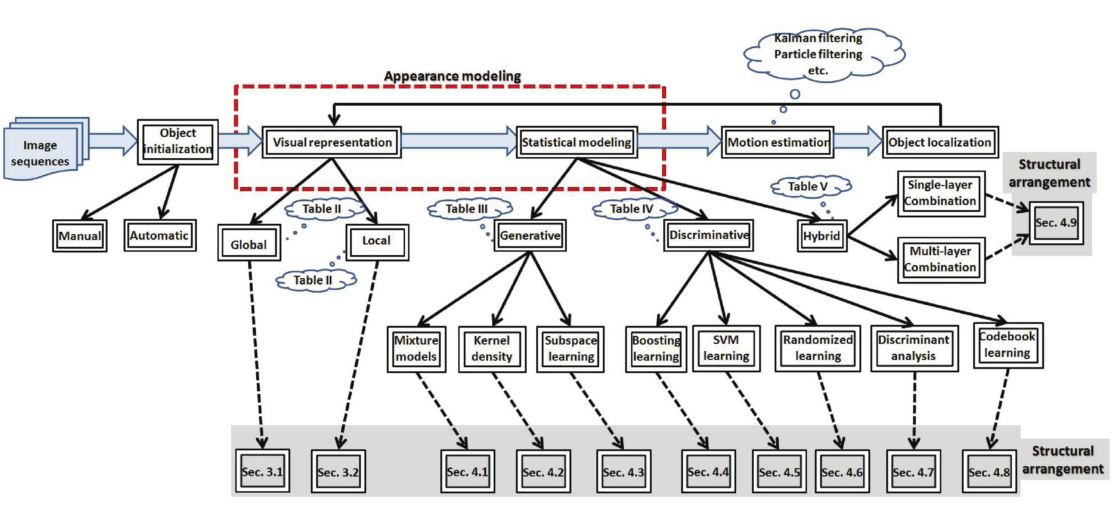
Contribution
- Review the literature of visual representations from a feature-construction viewpoint. Categorize the representation into local and global features.
- Classify the existing model into generative, discriminative, and hybrid generative-discriminative.
- Give some benchmark resources.
贡献如上
Visual Represetation
Representation is classified into local and global to introduce.
视觉表达可以分成全局和局部。
Global
Raw Pixel Representation
Simple and efficient, construct in vector-based or matrix-based.
Optical Flow Representation
It has two branches: constant-brightness-constraint optical flow and non-brightness-constraint optical flow.
Histogram Representation
single-cue
encode the information in the object region.
multi-cue
encode more information to enhance the robusness of visual represetation.
a. Spatial Color
joint spatial-color modeling(describe the distribution properties of object appearance in a joint spatial-color space) and patch-division.
b. Spatial Texture
An estimate of the joint spatial-texture probability is made to capture the distribution information on object appearance.
c. Shape Texture
Covariance Representations
the covariance matrix representations can be divided into two branches: affine-invariant Riemannian metric-based and log-Euclidean Riemannian metric-based.
- The affine-invariant Riemannian metric
$$\rho(\textbf{C}1,\textbf{C}_2)=\sqrt{\sum{j=1}^d ln^2\lambda_j(\mathbf{C}_1,\textbf{C}_2)}$$
- The log-Euclidean Riemannian metric
$$d(C_i,C_j)=||\log (C_i,C_j)||$$
Wavelet Filtering-Based Representation
a wavelet filtering-based representation takes advantage of wavelet transforms to filter the object region in different scales or directions
Active Contour Representation
In order to track the nonrigid objects, active contour representations have been widely used.
Discussion
原始的pixel特征简单,但是只考虑了颜色信息,不能克服光照变化。
在亮度不变的前提下,CBC光流能包含场信息,但是假设是亮度不变,所以不适应有噪点、光照变化和局部形变,NBC光流由此改进。
single-cue直方图作为统计特征,会失去目标的空间特性,一般会收到背景的影响,spatial-color直方图可以结合空间特性,shape-texture直方图包含形状和纹理信息,可以克服光照变化和姿势变化。
互相关矩阵有以下优点:
- 能使用目标表观的互相关性;
- 能够融合不同模态的图像特征;
- 维度低,计算高效;
- 能对比不同大小的区域;
- 比较容易实现;
- 光照不变、抗形变和遮挡。
缺点有:
- 容易受噪声影响;
- 丢失了很多信息,比如纹理、形状、位置。
小波滤波通过小波变换结合了局部的纹理信息,多尺度多方向表达了目标的统计特性。
活动轮廓可以解决非刚性物体的跟踪。
Local Feature-Based Visual Representation
Classify into seven classes: local template-based, segmentation-based, SIFT-based, MSER-based, SURF-based, corner feature-based, feature pool-based, and saliency detection-based
Local Template-Based
Represent an object region using a set of part templates.
Segmentation-Based
A segmentation-based visual representation incorporates the image segmentation cues
SIFT-based
Making use of the SIFT features inside an object region to describe the structural information of ob-ject appearance.
MSER-Based
An MSER-based visual representation needs to extract the MSER (maximally stable extremal region) features for visual representation
SURF-Based
the SURF (Speeded Up Robust Feature) is a variant of SIFT
Corner Feature-Based
Local Feature-Pool-Based
Saliency Detection-Based
Saliency detection is inspired by the focus-of-attention (FoA) theory
Discussion
基于局部模板的表达,能够应对遮挡问题。
基于分割的表达可以得到目标的结构化特征(例如目标边缘和超像素)。
基于SIFT特征的表达对光照、形变和遮挡有鲁棒性,但是不能包含目标的大小,方向和姿势等特征。
基于MSER(最大稳定极值区域)的表达可以容忍噪音但是不能克服光照变化。
基于SURF特征的表达具有尺度不变、旋转不变和计算高效的优点。
基于角点的特征表达对有大量角点的目标比较适用,但是不能应对形变和噪声。
基于池化的特征表达。
基于Saliency的特征表达。
Statistical Modeling For Tracking-By-Detection
The statistical modeling is classified into three categories, including generative, discriminative, and hybrid generatice-discriminative.
The generative appearance models mainly concentrate on how to accurately fit the data from the object class, but suffer from distractions caused by the background regions with similar appearance to the object class.
Discriminative appearance models pose visual object tracking as a
binary classification issue. They aim to maximize the separability between the object and non-object regions discriminately. A major limitation of the discriminative appearance models is to rely heavily on training sample selection.
Due to taking a heuristic fusion strategy, HGDAMs(hybrid generative-discriminative appearance models) cannot guarantee that the performance of the hybrid models after information fusion is better than those of the individual models.
Mixture Generative Appearance Models
This type of generative appearance model adaptively learns several compo- nents for capturing the spatiotemporal diversity of object appearance containing WSL mixture models and Gaussian mixture models.
WSL Mixture Models
the WSL mixture model contains the following three components: W-component, S-component, and L- component.
Robust Online Appearance Models for Visual Tracking and
Visual Tracking and Recognition Using Appearance-Adaptive Models in Particle Filters.
Gaussian Mixture Models
In essence, the Gaussian mixture models utilize a set of Gaussian distributions to approximate the underlying density function of object appearance.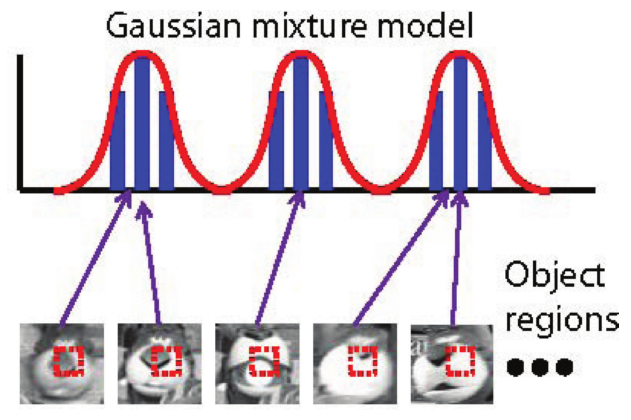
Kernel-Based Generative Appearance Models
Kernel-based generative appearance models(KGAMs)utilize kernel density estimation to construct kernel-based visual representations and then carry out the mean shift for object localization.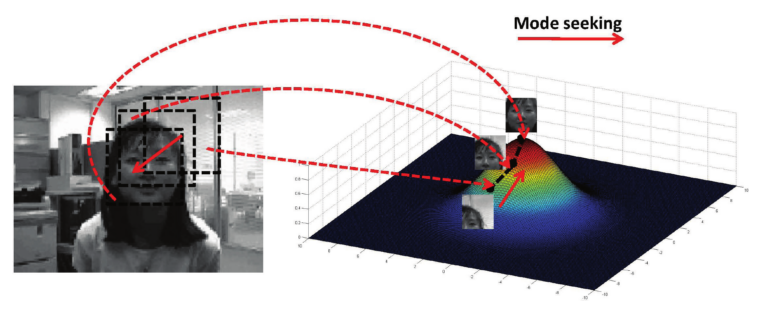
Including color-driven KGAMs, shape-integration KGAMs, scale-aware KGAMs, nonsymmetric KGAMs, KGAMs by global mode seeking, and sequential-kernel-learning KGAMs.
Subspace Learning-Based Generative Appearance Models
According to the used techniques for subspace analysis, they can be categorized into two types: conventional and unconventional SLGAMs.
Boosting-Based Discriminative Appearance Models
According to the learning strategies employed, they can be categorized into self-learning and co-learning BDAMs.
Self-learning-based BDAMs adopt the self-learning strategy to learn object/non-object classifier.In order to tackle this problem, co-learning-based BDAMs are developed to capture the discriminative information from many unlabeled samples in each frame.
SVM-Based Discriminative Appearance Models
SDAMs aim to learn margin-based discriminative SVM classifiers for maximizing in- terclass separability. SDAMs are typically based on self-learning SDAMs and co-learning SDAMs.
Randomized Learning-Based Discriminative Appearance Models
In principle, randomized learning techniques can build a diverse classifier ensemble by performing random input selec- tion and random feature selection.
Discriminant Analysis-Based Discriminative Appearance Models
In principle, its goal is to find a low-dimensional subspace with a high interclass separability. According to the learning schemes used, it can be split into two branches: conventional discriminant analysis and graph-driven discriminant analysis. However, a drawback is that these algorithms need to retain a large amount of labeled/unlabeled samples for graph learning, leading to their impracticality for real tracking applications.
Codebook Learning-Based Discriminative Appearance Models
CLDAMs need to constructed the foreground and background codebooks to adaptively capture the dynamic appearance information from the foreground and background.
实际上codebook需要的训练集太大,在实际应用中不是很方便。
Hybrid Generative-Discriminative Appearance Models
the generative and the discriminative mod- els have their own advantages and disadvantages and are complementary to each other to some extent.
结合产生和判别模型的优点。